
目前MikuBlog,MikuShare都支持HTTP/2了,别的站点因为CDN不支持,所以没办法,源站是支持的。目前我用的CDN只有腾讯云以及UPYUN支持HTTP/2,阿里云是不支持的,至少目前不支持。HTTP/2有好处吗,有是有的,不过日常可能感觉不到。
HTTP/2 的主要设计思想应该都是源自 Google的 SPDY 协议,是互联网工程任务组 ( IETF ) 对谷歌提出的 SPDY 协议进行标准化才有了现在的 HTTP/2 。下面我们直奔主题分析 HTTP/2 的新特性,并且与 HTTP/1.x作对比。
一、多路复用的单一长连接
1.单一长连接
在HTTP/2中,客户端向某个域名的服务器请求页面的过程中,只会创建一条TCP连接,即使这页面可能包含上百个资源。而之前的HTTP/1.x一般会创建6-8条TCP连接来请求这100多个资源。单一的连接应该是HTTP2的主要优势,单一的连接能减少TCP握手带来的时延(如果是建立在SSL/TLS上面,HTTP2能减少很多不必要的SSL握手,大家都知道SSL握手很慢吧)。
另外我们知道,TCP协议有个滑动窗口,有慢启动这回事,就是说每次建立新连接后,数据先是慢慢地传,然后滑动窗口慢慢变大,才能较高速度地传,这下倒好,这条连接的滑动窗口刚刚变大,http1.x就创个新连接传数据(这就好比人家HTTP2一直在高速上一直开着,你HTTP1.x是一辆公交车走走停停)。由于这种原因,让原本就具有突发性和短时性的 HTTP 连接变的十分低效。
所以咯,HTTP2中用一条单一的长连接,避免了创建多个TCP连接带来的网络开销,提高了吞吐量。
2.多路复用
明明是一条连接,怎么又是多路复用呢?后台开发的童鞋应该对多路复用很熟悉,例如用select,poll,epoll来管理一堆的fd,在这里,HTTP2虽然只有一条TCP连接,但是在逻辑上分成了很多stream。这个特性又很关键呐。先看下面这个网上借用的图 。
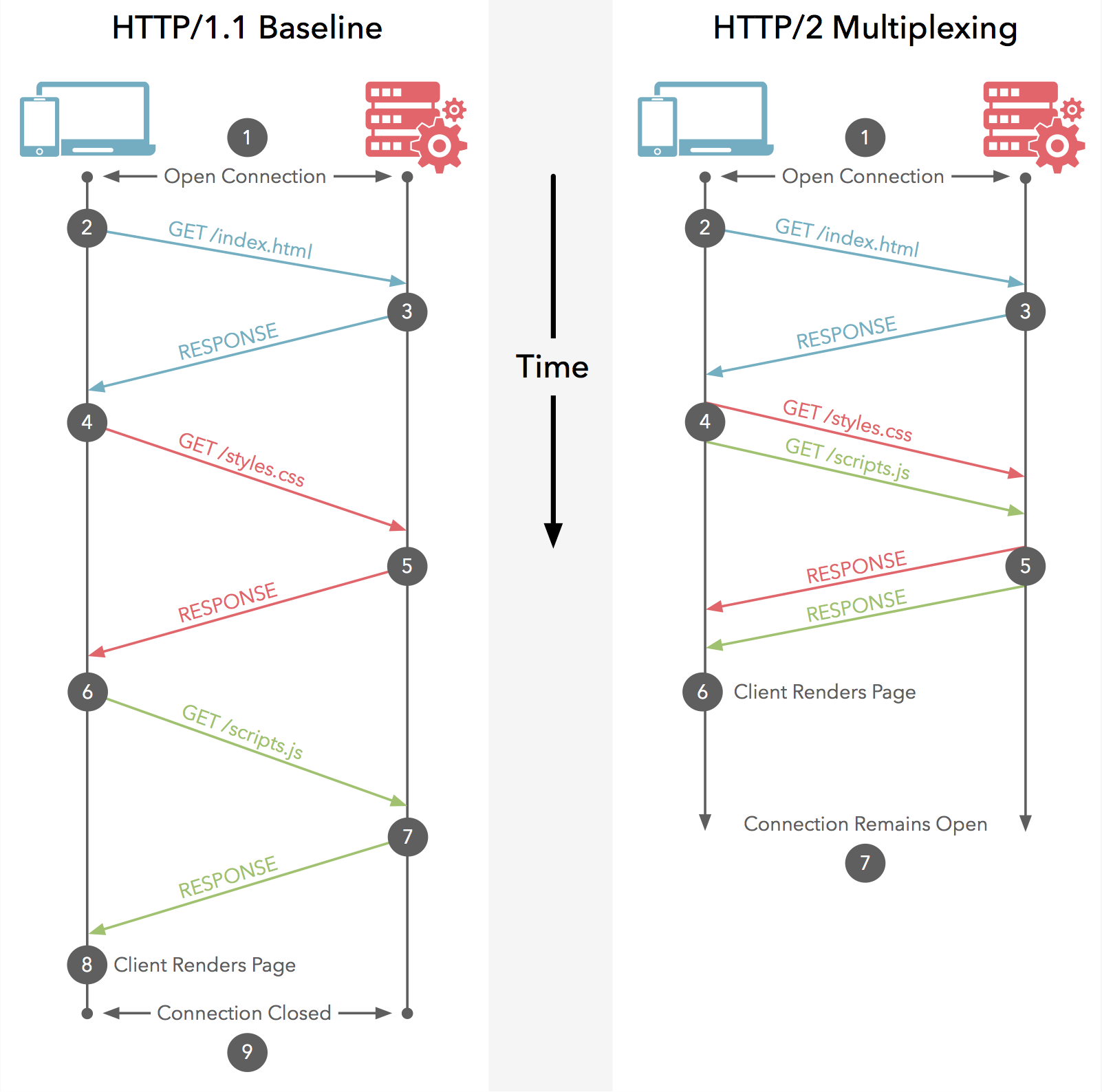
以前的http1.x怎么干的?在一条TCP连接上,多个请求只能串行执行!你说咱们现在的网络带宽这么大,这不浪费吗?http2就不一样了,不管多少请求,只要有,就往连接里面扔好了,这能明显降低一个页面加载的时间。
HTTP2多路复用怎么做到的?又来打个比方,你看高速公路,虽然路只有一条,但是收费的那个门是不是有很多个?
HTTP2把要传输的信息分割成一个个二进制帧,首部信息会被封装到HEADER Frame,相应的request body就放到DATA Frame,一个帧你可以看成路上的一辆车,只要给这些车编号,让1号车都走1号门出,2号车都走2号门出,就把不同的http请求或者响应区分开来了。但是,这里要求同一个请求或者响应的帧必须是有有序的,要保证FIFO的,但是不同的请求或者响应帧可以互相穿插。这就是HTTP2的多路复用,是不是充分利用了网络带宽,是不是提高了并发度?
更进一步,http2还能对这些流(车道)指定优先级,优先级能动态的被改变,例如把CSS和JavaScript文件设置得比图片的优先级要高,这样代码文件能更快的下载下来并得到执行。
现在回过头来看下,请求一个包含几十个或者几百个资源的页面,HTTP1.x和HTTP2在过程上面的区别,如下图所示:

我想英文不捉鸡的同学应该都能看懂,这里http1.x建了6到8个tcp连接后,一个个请求串行地用这八个连接执行,而http2能一次把所有请求都发出去,还是压缩过的,高下立判。
二、头部压缩和二进制格式
http1.x一直都是plain text,对此我只能想到一个优点,便于阅读和debug。但是,现在很多都走https,SSL也把plain text变成了二进制,那这个优点也没了。
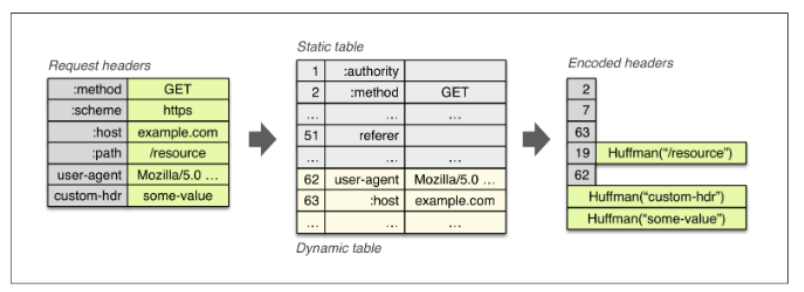
于是HTTP2搞了个HPACK压缩来压缩头部,减少报文大小(调试这样的协议将需要curl这样的工具,要进一步地分析网络数据流需要类似Wireshark的http2解析器)。HPACK把报文中常见的字段名和值变成一个索引值index,也就是维护了一张静态索引表,例如把 method: GET对应成索引表中index为2的一个值,但是头部还有一些不确定的东西,比如user-agent对应的浏览器名字啊。
所以它也维护了一个动态的索引表,静态表索引值为2-61,这时候数据传输过程中发现一个user-agent Mozilla/5.0,那就把这个追加到动态索引表值为62的地方,这次开始就用62代替这个user-agent Mozilla/5.0,所以这个动态索引表是在数据传输过程中逐步建立的,静态索引表写死的。
此外,对于资源路径这种完全不确定的东西,HPACK就采用Huffman编码来压缩,这样三管齐下,头部内容能大幅减少。可以看看下面的HPACK示意图:
头部为什么需要压缩?
因为一些重复东西在每个http请求里面都有,例如method: GET。当一个客户端从同一服务器请求一些资源(例如页面的图片)的时候,这些请求看起来几乎是一致的。而这些大量一致的东西正好值得被压缩。
另外,HTTP 1.1请求的大小变得越来越大,有时甚至会大于TCP窗口的初始大小,这会严重拖累发送请求的速度。因为它们需要等待带着ACK的响应回来以后,才能继续被发送。尤其是当http请求内容超过TCP报文最大报文大小时,会被分成几个TCP报文,这时候如果压缩,能减少了tcp报文个数,就能减少几个RTT时间了。
反过来,头部压缩也带来了CPU消耗,而且如果刚好头部能被装到一个TCP报文里面,压缩也没什么卵用。而且大部分响应报文的body一般比header大很多,这时候好像压缩头部也是多此一举。
三、服务端推送Server Push
这个功能通常被称作“缓存推送”。主要的思想是:当一个客户端请求资源X,而服务器知道它很可能也需要资源Z的情况下,服务器可以在客户端发送请求前,主动将资源Z推送给客户端。
这个功能帮助客户端将Z放进缓存以备将来之需。服务器推送需要客户端显式的允许服务器提供该功能。但即使如此,客户端依然能自主选择是否需要中断该推送的流。如果不需要的话,客户端可以通过发送一个RST_STREAM帧来中止。
以上就是HTTP最主要的几个新特性啦(当然还有很多新特性,这里不详谈啦)。最后安利一下HTTP2 + SSL吧,貌似目前浏览器只有在服务器支持http2并且使用了SSL的时候才会使用http2协议。总结一下为什么HTTP2能去掉SSL在HTTP1.x上的开销?
1.单一的长连接,减少了SSL握手的开销
2.头部被压缩,减少了数据传输量
3.多路复用能大幅提高传输效率,不用等待上一个请求的响应
4.不用像http1.x那样把多个文件或者资源弄成一个文件或者资源(http1.x常见的优化手段),这时候,缓存就能更容易命中啊(http1.x里面你揉成一团的东西怎么命中缓存?)
转自:腾云阁
😆 😆 不明觉厉